Оценка доверительных интервалов
Цели обучения
Статистика рассматривает следующие две основные задачи :
У нас есть некоторая оценка, построенная на выборочных данных, и мы хотим сделать некоторое вероятностное утверждение относительно того, где находится истинное значение оцениваемого параметра.
У нас есть конкретная гипотеза, которую необходимо проверить на основе выборочных данных.
В данной теме мы рассматриваем первую задачу. Введем также определение доверительного интервала.
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Изучив материал данной темы, Вы:
узнаете, что такое доверительный интервал оценки;
научитесь классифицировать статистические задачи;
освоите технику построения доверительных интервалов, как по статистическим формулам, так и с помощью программного инструментария;
научитесь определять необходимые размеры выборок для достижения определенных параметров точности статистических оценок.
Распределения выборочных характеристик
Т-распределение
Как обсуждали выше распределение случайной величины близко к стандартизованному нормальному распределению с параметрами 0 и 1. Поскольку нам не известна величина σ, мы заменяем ее на некоторую оценку s . Величина уже имеет другое распределение, а именно или Распределение Стьюдента , которое определяется параметром n -1 (число степеней свободы). Это распределение близко к нормальному распределению (чем больше n , тем распределения ближе).
На рис. 95  представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
Аналогично функциям для работы с нормальным распределением НОРМРАСП
и НОРМОБР
имеются функции для работы с t-распределением - СТЬЮДРАСП (TDIST)
и СТЬЮДРАСПОБР (TINV)
. Пример использования этих функций можно посмотреть в файле СТЬЮДРАСП.XLS (шаблон
и решение
) и на рис. 96  .
.
Распределения других характеристик
Как мы уже знаем, для определения точности оценивания математического ожидания нам необходимо t-распределение. Для оценивания других параметров, например, дисперсии, требуются другие распределения. Два из них - это F-распределение и x 2 -распределение .
Доверительный интервал для среднего значения
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Построение доверительного интервала для среднего значения происходит следующим образом :
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать 40 посетителей из тех, кто уже попробовал его и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. Как это осуществить? (см. файл СЭНДВИЧ1.XLS (шаблон и решение ).
Решение
Для решения данной задачи можно воспользоваться . Результаты представлены на рис. 97  .
.
Доверительный интервал для суммарного значения
Иногда по выборочным данным требуется оценить не математическое ожидание, а общую сумму значений. Например, в ситуации с аудитором интерес может представлять оценка не средней величины счета, а суммы всех счетов.
Пусть N
- общее количество элементов, n
- размер выборки, T 3
- сумма значений в выборке, T" - оценка для суммы по всей совокупности, тогда ![]() , а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
, а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
Пример
Допустим, некоторая налоговая служба хочет оценить размер суммарных налоговых возвратов для 10 000 налогоплательщиков. Налогоплательщик либо получает возврат, либо доплачивает налоги. Найдите 95%-й доверительный интервал для суммы возврата при условии, что размер выборки составляет 500 человек (см. файл СУММА ВОЗВРАТОВ.XLS (шаблон и решение ).
Решение
В StatPro
нет специальной процедуры для этого случая, однако можно заметить, что границы можно получить из границ для среднего исходя из вышеприведенных формул (рис. 98  ).
).
Доверительный интервал для пропорции
Пусть p - математическое ожидание доли клиентов, а р в
- оценка этой доли, полученная по выборке размера n. Можно показать, что для достаточно больших  распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением
распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением ![]() . Стандартная ошибка оценки в данном случае выражается как
. Стандартная ошибка оценки в данном случае выражается как  , а доверительный интервал как
, а доверительный интервал как  .
.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом выбрал 40 посетителей из тех, кто уже попробовал его и предложил им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемую долю клиентов, которые оценивают новый продукт не менее чем в 6 баллов (он ожидает, что именно эти клиенты и будут потребителями нового продукта).
Решение
Первоначально создаем новый столбец по признаку 1, если оценка клиента была больше 6 баллов и 0 иначе (см. файл СЭНДВИЧ2.XLS (шаблон и решение ).
Способ 1
Подсчитывая количество 1, оцениваем долю, а далее используем формулы.
Значение z кр берется из специальных таблиц нормального распределения (например, 1,96 для 95%-го доверительного интервала).
Используя данный подход и конкретные данные для построения 95%-го интервала, получим следующие результаты (рис. 99  ). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
Способ 2
Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно заметить, что доля в данном случае совпадает со средним значением столбца Тип . Далее применим StatPro/Statistical Inference/One-Sample Analysis для построения доверительного интервала среднего значения (оценки математического ожидания) для столбца Тип . Полученные в этом случае результат, будут весьма близок к результату 1-го способа (рис. 99).
Доверительный интервал для стандартного отклонения
В качестве оценки стандартного отклонения используется s (формула приведена в разделе 1). Функцией плотности распределения оценки s является функция хи-квадрат , которая, как и t-распределение, имеет n-1 степень свободы. Имеются специальные функции для работы с этим распределением ХИ2РАСП (CHIDIST) и ХИ2ОБР (CHIINV) .
Доверительный интервал в этом случае уже будет не симметричным. Условная схема границ представлена на рис. 100 .
Пример
Станок должен производить детали диаметром 10 см. Однако в силу различных обстоятельств происходят ошибки. Контролера по качеству волнуют два обстоятельства: во-первых, среднее значение должно равняться 10 см; во-вторых, даже в этом случае, если отклонения будут велики, то многие детали будут забракованы. Ежедневно он делает выборку из 50 деталей (см. файл КОНТРОЛЬ КАЧЕСТВА.XLS (шаблон и решение ). Какие выводы может дать такая выборка?
Решение
Построим 95%-й доверительные интервалы для среднего и для стандартного отклонения с помощью StatPro/Statistical Inference/ One-Sample Analysis
(рис. 101  ).
).
Далее, используя предположение о нормальном распределении диаметров, рассчитаем долю бракованных изделий, задавшись предельным отклонением 0,065. Используя возможности таблицы подстановки (случай двух параметров), построим зависимость доли брака от среднего значения и стандартного отклонения (рис. 102  ).
).
Доверительный интервал для разности двух средних значений
Это одно из наиболее важных применений статистических методов. Примеры ситуаций.
Менеджер магазина одежды хотел бы знать, на сколько больше или меньше тратит в магазине средняя женщина-покупатель, чем мужчина.
Две авиакомпании летают аналогичными маршрутами. Организация-потребитель хотела бы сравнить разницу между среднеожидаемыми временами задержек рейсов по обеим авиакомпаниям.
Компания рассылает купоны на отдельные виды товаров в одном городе и не рассылает в другом. Менеджеры хотят сравнить средние объемы покупок этих товаров в ближайшие два месяца.
Автомобильный дилер часто имеет дело на презентациях с замужними парами. Чтобы понять их персональную реакцию на презентацию, пары часто опрашивают отдельно. Менеджер хочет оценить разницу в рейтингах указываемых мужчинами и женщинами.
Случай независимых выборок
Разность средних значений будет иметь t-распределение с n 1 + n 2 - 2 степенями свободы. Доверительный интервал для μ 1 - μ 2 выражается соотношением:

Данная задача допускает решение не только по вышеприведенным формулам, но и стандартными средствами StatPro . Для этого достаточно применить
Доверительный интервал для разности между пропорциями
Пусть - математическое ожидание долей. Пусть - их выборочные оценки, построенные по выборкам размера n 1 и n 2 соответственно. Тогда является оценкой для разности . Следовательно, доверительный интервал этой разности выражается как:
Здесь z кр является значением, полученным из нормального распределения по специальным таблицам (например, 1,96 для 95%-й доверительного интервала).
Стандартная ошибка оценки выражается в данном случае соотношением:
 .
.
Пример
Магазин, готовясь к большой распродаже, предпринял следующие маркетинговые исследования. Были выбраны 300 лучших покупателей, которые в свою очередь были случайным образом поделены на две группы по 150 членов в каждой. Всем из отобранных покупателей были разосланы приглашения для участия в распродаже, но только для членов первой группы был приложен купон, дающий право на скидку 5%. В ходе распродажи покупки всех 300 отобранных покупателей фиксировались. Каким образом менеджер может интерпретировать полученные результаты и сделать заключение об эффективности предоставления купонов? (см. файл КУПОНЫ.XLS (шаблон и решение )).
Решение
Для нашего конкретного случая из 150 покупателей, получивших купон на скидку, 55 сделали покупку на распродаже, а среди 150, не получивших купон, покупку сделали только 35 (рис. 103  ). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
50 0,2333 100 = 1166,50 руб.
Аналогичные вычисления для 100 покупателей получивших купон, дают:
30 0,3667 100 = 1100,10 руб.
Уменьшение средней прибыли до 30 объясняется тем, что, используя скидку, покупатели, получившие купон, в среднем будут делать покупку на 380 руб.
Таким образом, итоговый вывод говорит о неэффективности использования таких купонов в данной конкретной ситуации.
Замечание. Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно свести данную задачу к задаче оценки разности двух средних способом, а далее применить StatPro/Statistical Inference/Two-Sample Analysis для построения доверительного интервала разности двух средних значений.
Управление длиной доверительного интервала
Длина доверительного интервала зависит от следующих условий :
непосредственно данных (стандартное отклонение);
уровня значимости;
размера выборки.
Размер выборки для оценки среднего значения
Сначала рассмотрим задачу в общем случае. Обозначим данное нам значение половины длины доверительного интервала за В
(рис. 104  ). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как
). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как ![]() , где
, где ![]() . Полагая:
. Полагая:
![]() и выражая n
, получим .
и выражая n
, получим .
К сожалению, точное значение дисперсии случайной величины X нам не известно. Кроме этого, нам неизвестно и значение t кр , так как оно зависит от n через количество степеней свободы. В данной ситуации мы можем поступить следующим образом. Вместо дисперсии s используем какую-либо оценку дисперсии, по каким-либо имеющимся реализациям исследуемой случайной величины. Вместо значения t кр используем значение z кр для нормального распределения. Это вполне допустимо, поскольку функции плотности распределений для нормального и t-распределения очень близки (за исключением случая малых n ). Таким образом, искомая формула принимает вид:
 .
.
Поскольку формула дает, вообще говоря, нецелочисленные результат, в качестве искомого размера выборки берется округление с избытком результата.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать некоторое количество посетителей из тех, кто уже попробовал его, и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. При этом он хочет, чтобы половина ширины доверительного интервала не превышала 0,3. Какое количество посетителей ему необходимо опросить?
выглядит следующим образом:

Здесь р оц - оценка доли p , а В есть заданная половина длины доверительного интервала. Завышенное значение для n можно получить, используя значение р оц = 0,5. В этом случае длина доверительного интервала не будет превосходить заданного значения В при любом истинном значении p .
Пример
Пусть менеджер из предыдущего примера планирует оценить долю клиентов, отдавших предпочтение новому виду продукции. Он хочет построить 90%-й доверительный интервал, половина длины которого не превосходила бы 0,05. Сколько клиентов должно войти в случайную выборку?
Решение
В нашем случае значение z кр
= 1,645. Поэтому искомое количество вычисляется как  .
.
Если бы менеджер имел основания полагать, что искомое значение p составляет, например, примерно 0,3, то, подставляя это значение в вышеприведенную формулу, мы получили бы меньшее значение величины случайной выборки, а именно 228.
Формула для определения размеров случайной выборки в случае разности между двумя средними значениями записывается как:
 .
.
Пример
Некоторая компьютерная компания имеет сервисный центр по обслуживанию клиентов. В последнее время увеличилось количество жалоб клиентов на плохое качество обслуживания. В сервисном центре в основном работают сотрудники двух типов: не имеющие большого опыта, но закончившие специальные подготовительные курсы, и имеющие большой практический опыт, но не закончившие специальных курсов. Компания хочет проанализировать нарекания клиентов за последние полгода и сравнить их средние количества, приходящиеся на каждую из двух групп сотрудников. Предполагается, что количества в выборках по обеим группам будут одинаковые. Какое количество сотрудников необходимо включить в выборку, чтобы получить 95%-й интервал с половиной длины не более 2?
Решение
Здесь σ оц есть оценка стандартного отклонения обеих случайных переменных в предположении, что они близки. Таким образом, в нашей задаче нам необходимо каким-то образом получить эту оценку. Это можно сделать, например, следующим образом. Просмотрев данные по нареканиям клиентов за последние полгода, менеджер может заметить, что на каждого сотрудника в основном приходится от 6 до 36 нареканий. Зная, что для нормального распределения практически все значения удалены от среднего значения не более чем на три стандартных отклонения, он может с определенным основанием полагать, что:
![]() , откуда σ оц
= 5.
, откуда σ оц
= 5.
Подставляя это значение в формулу, получаем  .
.
Формула для определения размера случайной выборки в случае оценки разности между долями имеет вид:

Пример
Некоторая компания имеет две фабрики по производству аналогичной продукции. Менеджер компании хочет сравнить доли бракованной продукции на обеих фабриках. По имеющейся информации процент брака на обеих фабриках составляет от 3 до 5%. Предполагается построить 99%-й доверительный интервал с половиной длины не более 0,005 (или 0,5%). Какое количество изделий необходимо отобрать с каждой фабрики?
Решение
Здесь р 1оц и р 2оц являются оценками двух неизвестных долей брака на 1-й и 2-й фабрике. Если положить р 1оц = р 2оц = 0,5, то мы получим завышенное значение для n . Но поскольку в нашем случае мы имеем некоторую априорную информацию об этих долях, то мы берем верхнюю оценку этих долей, а именно 0,05. Получаем
Когда делается оценка некоторых параметров совокупности по выборочным данным, полезно дать не только точечную оценку параметра, но и указать доверительный интервал, который показывает, где может находиться точное значение оцениваемого параметра.
В данной главе мы также познакомились с количественными соотношениями, позволяющими строить такие интервалы для различных параметров; узнали способы управления длиной доверительного интервала.
Отметим также, что задачу оценки размеров выборки (задача планирования эксперимента) можно решить, используя стандартные средства StatPro , а именно StatPro/Statistical Inference/Sample Size Selection .
Доверительный интервал пришел к нам из области статистики. Это определенный диапазон, который служит для оценки неизвестного параметра с высокой степенью надежности. Проще всего это будет пояснить на примере.
Предположим, нужно исследовать какую-либо случайную величину, например, скорость отклика сервера на запрос клиента. Каждый раз, когда пользователь набирает адрес конкретного сайта, сервер реагирует на это с разной скоростью. Таким образом, исследуемое время отклика имеет случайный характер. Так вот, доверительный интервал позволяет определить границы этого параметра, и затем можно будет утверждать, что с вероятностью в 95% сервера будет находиться в рассчитанном нами диапазоне.
Или же нужно узнать, какому количеству людей известно о торговой марке фирмы. Когда будет подсчитан доверительный интервал, то можно будет, к примеру, сказать что с 95% долей вероятности доля потребителей, знающих о данной находится в диапазоне от 27% до 34%.
С этим термином тесно связана такая величина, как доверительная вероятность. Она представляет собой вероятность того, что искомый параметр входит в доверительный интервал. От этой величины зависит то, насколько большим окажется наш искомый диапазон. Чем большее значение она принимает, тем уже становится доверительный интервал, и наоборот. Обычно ее устанавливают равной 90%, 95% или 99%. Величина 95% наиболее популярна.
На данный показатель также оказывает влияние дисперсия наблюдений и Его определение основано на том предположении, что исследуемый признак подчиняется Это утверждение известно также как Закон Гаусса. Согласно ему, нормальным называется такое распределение всех вероятностей непрерывной случайной величины, которое можно описать плотностью вероятностей. Если предположение о нормальном распределении оказалось ошибочным, то оценка может оказаться неверной.
Сначала разберемся с тем, как вычислить доверительный интервал для Здесь возможны два случая. Дисперсия (степень разброса случайной величины) может быть известна либо нет. Если она известна, то наш доверительный интервал вычисляется с помощью следующей формулы:
хср - t*σ / (sqrt(n)) <= α <= хср + t*σ / (sqrt(n)), где
α - признак,
t - параметр из таблицы распределения Лапласа,
σ - квадратный корень дисперсии.
Если дисперсия неизвестна, то ее можно рассчитать, если нам известны все значения искомого признака. Для этого используется следующая формула:
σ2 = х2ср - (хср)2, где
х2ср - среднее значение квадратов исследуемого признака,
(хср)2 - квадрат данного признака.
Формула, по которой в этом случае рассчитывается доверительный интервал немного меняется:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n)), где
хср - выборочное среднее,
α - признак,
t - параметр, который находят с помощью таблицы распределения Стьюдента t = t(ɣ;n-1),
sqrt(n) - квадратный корень общего объема выборки,
s - квадратный корень дисперсии.
Рассмотри такой пример. Предположим, что по результатам 7 замеров была определена исследуемого признака, равная 30 и дисперсия выборки, равная 36. Нужно найти с вероятностью в 99% доверительный интервал, который содержит истинное значение измеряемого параметра.
Вначале определим чему равно t: t = t (0,99; 7-1) = 3.71. Используем приведенную выше формулу, получаем:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7)) <= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Доверительный интервал для дисперсии рассчитывается как в случае с известным средним, так и тогда, когда нет никаких данных о математическом ожидании, а известно лишь значение точечной несмещенной оценки дисперсии. Мы не будем приводить здесь формулы его расчета, так как они довольно сложные и при желании их всегда можно найти в сети.
Отметим лишь, что доверительный интервал удобно определять с помощью программы Excel или сетевого сервиса, который так и называется.
Из данной статьи вы узнаете:
Что такое доверительный интервал ?
В чем суть правила 3-х сигм ?
Как можно применить эти знания на практике?
В наше время из-за переизбытка информации, связанного с большим ассортиментом товаров, направлений продаж, сотрудников, направлений деятельности и т.д., бывает трудно выделить главное , на что, в первую очередь, стоит обратить внимание и приложить усилия для управления. Определение доверительного интервала и анализ выхода за его границы фактических значений - методика, которая поможет вам выделить ситуации , влияющие на изменение тенденций. Вы сможете развивать позитивные факторы и снизить влияние негативных. Данная технология применяется во многих известных мировых компаниях.
Существуют так называемые "оповещения" , которые информируют руководителей о том, что очередное значение в определенном направлении вышло за доверительный интервал . Что это означает? Это сигнал, что произошло какое-то нестандартное событие, которое, возможно, изменит существующую тенденцию в данном направлении. Это сигнал к тому, чтобы разобраться в ситуации и понять, что на неё повлияло.
Например, рассмотрим несколько ситуаций. Мы рассчитали прогноз продаж с границами прогноза по 100 товарным позициям на 2011 год по месяцам и в марте фактические продажи:
По остальным товарам фактические продажи оказались в рамках заданных границ прогноза. Т.е. их продажи оказались в рамках ожиданий. Итак, мы выделили 3 товара, которые вышли за границы, и начали разбираться, что же повлияло на выход за границы:
Мы выделили 3 фактора, которые повлияли на выход за границы прогноза. В жизни их может быть гораздо больше.Для повышения точности прогнозирования и планирования факторы, которые приводят к тому, что фактические продажи могут выйти за границы прогноза, стоит выделить и строить прогнозы и планы по ним отдельно. А затем учитывать их влияние на основной прогноз продаж. Также можно регулярно оценивать влияние данных факторов и менять ситуацию к лучшему за счет уменьшения влияния негативных и увеличения влияния позитивных факторов .
Теперь рассмотрим, что такое доверительный интервал и как его рассчитать в Excel на примере.
Доверительный интервал – это границы прогноза (верхняя и нижняя), в рамки которых с заданной вероятностью (сигма) попадут фактические значения.
Т.е. мы рассчитываем прогноз - это наш основной ориентир, но мы понимаем, что фактические значения вряд ли на 100% будут равны нашему прогнозу. И возникает вопрос, в какие границы могут попасть фактические значения, если существующая тенденция сохранится ? И на этот вопрос нам поможет ответить расчет доверительного интервала , т.е. - верхней и нижней границы прогноза.
При расчете доверительного интервала мы можем задать вероятность попадания фактических значений в заданные границы прогноза . Как это сделать? Для этого мы задаем значение сигма и, если сигма будет равна:
3 сигма - то, вероятность попадания очередного фактического значения в доверительный интервал составят 99,7%, или 300 к 1, или существует 0,3% вероятности выхода за границы.
2 сигма - то, вероятность попадания очередного значения в границы составляет ≈ 95,5 %, т.е. шансы примерно 20 к 1, или существует 4,5% вероятности выхода за границы.
1 сигма - то, вероятность ≈ 68,3%, т.е. шансы примерно 2 к 1, или существует 31,7% вероятность того, что очередное значение выйдет за пределы доверительного интервала.
Мы сформулировали правило 3 сигм, которое гласит, что вероятность попадания очередного случайного значения в доверительный интервал с заданным значением три сигма составляет 99.7% .
Великим русским математиком Чебышевым была доказана теорема о том, что существует 10% вероятность выхода за границы прогноза с заданным значением три сигма. Т.е. вероятность попадания в доверительный интервал 3 сигма составит минимум 90%, в то время как попытка рассчитать прогноз и его границы «на глазок» чревата куда более существенными ошибками.
Расчет доверительного интервала в Excel (т.е. верхней и нижней границы прогноза) рассмотрим на примере. У нас есть временной ряд - продажи по месяцам за 5 лет. См. Вложенный файл.
Для расчета границ прогноза рассчитаем:
=(RC[-14](данные во временном ряду) - RC[-1](значение модели) )^2(в квадрате)

3. Просуммируем для каждого месяца значения отклонений из 8 этапа Сумма((Xi-Ximod)^2), т.е. просуммируем январи, феврали... для каждого года.
Для этого воспользуемся формулой =СУММЕСЛИ()
СУММЕСЛИ(массив с номерами периодов внутри цикла (для месяцев от 1 до 12);ссылка на номер периода в цикле; ссылка на массив с квадратами разницы исходных данных и значений периодов)

4. Рассчитаем среднеквадратическое отклонение для каждого периода в цикле от 1 до 12 (10 этапво вложенном файле ).
Для этого из значения рассчитанного на 9 этапе мы извлекаем корень и делим на количество периодов в этом цикле минус 1 = КОРЕНЬ((Сумма(Xi-Ximod)^2/(n-1))
Воспользуемся формулами в Excel =КОРЕНЬ(R8 (ссылка на (Сумма(Xi-Ximod)^2) /(СЧЁТЕСЛИ($O$8:$O$67 (ссылка на массив с номерами цикла) ; O8 (ссылка на конкретный номер цикла, которые считаем в массиве) )-1))
С помощью формулы Excel = СЧЁТЕСЛИ мы считаем количество n

Рассчитав среднеквадратическое отклонение фактических данных от модели прогноза, мы получили значение сигма для каждого месяца - этап 10 во вложенном файле .
На 11 этапе задаем количество сигм - в нашем примере «3» (11 этапво вложенном файле ):

1,64 сигма - 10% вероятность выхода за предел (1 шанс из 10);
1,96 сигма - 5% вероятность выхода за пределы (1 шанс из 20);
2,6 сигма - 1% вероятность выхода за пределы (1 шанс из 100).
5) Рассчитываем три сигма , для этого мы значения «сигма» для каждого месяца умножаем на «3».

Для удобства расчета доверительного интервала на длительный период (см. вложенный файл) воспользуемся формулой Excel =Y8+ВПР(W8;$U$8:$V$19;2;0) , где
Y8 - прогноз продаж;
W8 - номер месяца, для которого будем брать значение 3-х сигма;
Т.е. Верхняя граница прогноза = «прогноз продаж» + «3 сигма» (в примере, ВПР(номер месяца; таблица со значениями 3-х сигма; столбец, из которого извлекаем значение сигма равное номеру месяца в соответствующей строке;0)).

Нижняя граница прогноза = «прогноз продаж» минус «3 сигма».
Итак, мы рассчитали доверительный интервал в Excel.
Теперь у нас есть прогноз и диапазон с границами в пределах, которого с заданной вероятностью сигма попадут фактические значения.
В данной статье мы рассмотрели, что такое сигма и правило трёх сигм, как определить доверительный интервал и для чего вы можете использовать данную методику на практике.
Чем Forecast4AC PRO может вам помочь при расчете доверительного интервала ?:
Forecast4AC PRO автоматически рассчитает верхнюю или нижнюю границы прогноза для более чем 1000 временных рядов одновременно;
Возможность анализа границ прогноза в сравнении с прогнозом, трендом и фактическими продажами на графике одним нажатием клавиши;
В программе Forcast4AC PRO есть возможность задать значение сигма от 1 до 3.
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа :

Тестируйте возможности платных решений:
«Катрен-Стиль» продолжает публикацию цикла Константина Кравчика о медицинской статистике. В двух предыдущих статьях автор касался объяснения таких понятий, как и .
Константин Кравчик
Математик-аналитик. Специалист в области статистических исследований в медицине и гуманитарных науках
Город: Москва
Очень часто в статьях по клиническим исследованиям можно встретить загадочное словосочетание: «доверительный интервал» (95 % ДИ или 95 % CI - confidence interval). Например, в статье может быть написано: «Для оценки значимости различий использовали t-критерий Стьюдента с расчетом 95 % доверительного интервала».
Какого же значение «95 % доверительного интервала» и зачем его рассчитывать?
Что такое доверительный интервал? - Это диапазон, в котором находятся истинные средние значения в генеральной совокупности. А что, бывают «неистинные» средние значения? В каком‑то смысле да, бывают. В мы объясняли, что невозможно измерить интересующий параметр во всей генеральной совокупности, поэтому исследователи довольствуются ограниченной выборкой. В этой выборке (например, по массе тела) есть одно среднее значение (определенный вес), по которому мы и судим о среднем значении во всей генеральной совокупности. Однако едва ли средний вес в выборке (особенно небольшой) совпадет со средним весом в генеральной совокупности. Поэтому более правильно рассчитывать и пользоваться диапазоном средних значений генеральной совокупности.
Например, представим, что 95 % доверительный интервал (95 % ДИ) по гемоглобину составляет от 110 до 122 г/л. Это означает, что с вероятностью 95 % истинное среднее значение по гемоглобину в генеральной совокупности будет находиться в пределах от 110 до 122 г/л. Иными словами, мы не знаем средний показатель гемоглобина в генеральной совокупности, но можем с 95 %-й вероятностью указать диапазон значений для этого признака.
Доверительный интервал особенно уместен для разницы в средних значениях между группами или, как это называют, в размере эффекта.
Допустим, мы сравнивали эффективность двух препаратов железа: давно присутствующего на рынке и только что зарегистрированного. После курса терапии оценили концентрацию гемоглобина в исследуемых группах пациентов, и статистическая программа нам посчитала, что разность между средними значениями двух групп с вероятностью 95 % находится в диапазоне от 1,72 до 14,36 г/л (табл. 1).
Табл. 1. Критерий для независимых выборок
(сравниваются группы по уровню гемоглобина)
Трактовать это следует так: у части пациентов генеральной совокупности, которая принимает новый препарат, гемоглобин будет выше в среднем на 1,72–14,36 г/л, чем у тех, кто принимал уже известный препарат.
Иными словами, в генеральной совокупности разность в средних значениях по гемоглобину у групп с 95 %-й вероятностью находится в этих пределах. Судить, много это или мало, будет уже исследователь. Смысл всего этого в том, что мы работаем не с одним средним значением, а с диапазоном значений, следовательно, мы более достоверно оцениваем разницу по параметру между группами.
В статистических пакетах, на усмотрение исследователя, можно самостоятельно сужать или расширять границы доверительного интервала. Снижая вероятности доверительного интервала, мы сужаем диапазон средних. Например, при 90 % ДИ диапазон средних (или разницы средних) будет уже, чем при 95 %.
И наоборот, увеличение вероятности до 99 % расширяет диапазон значений. При сравнении групп нижняя граница ДИ может пересечь нулевую отметку. Например, если мы расширили границы доверительного интервала до 99 %, то границы интервала расположились от –1 до 16 г/л. Это означает, что в генеральной совокупности есть группы, различие средних между которыми по изучаемому признаку равняется 0 (М=0).
При помощи доверительного интервала можно проверять статистические гипотезы. Если доверительный интервал пересекает нулевое значение, то нулевая гипотеза, предполагающая, что группы не различаются по изучаемому параметру, верна. Пример описан выше, когда мы расширили границы до 99 %. Где‑то в генеральной совокупности у нас нашлись группы, которые никак не различались.

На рисунке в виде линии изображен 95 % доверительный интервал разницы средних значений по гемоглобину между двумя группами. Линия проходит нулевую отметку, следовательно, имеет место разница между средними значениями, равная нулю, что подтверждает нулевую гипотезу о том, что группы не различаются. Диапазон разницы между группами лежит от –2 до 5 г/л, Это означает, что гемоглобин может как снизиться на 2 г/л, так и повыситься на 5 г/л.
Доверительный интервал - очень важный показатель. Благодаря ему можно посмотреть, были ли различия в группах действительно за счет разности средних или за счет большой выборки, т. к. при большой выборке шансы найти различия больше, чем при малой.
На практике это может выглядеть так. Мы взяли выборку в 1000 человек, измерили уровень гемоглобина и обнаружили, что доверительный интервал разницы средних лежит от 1,2 до 1,5 г/л. Уровень статистической значимости при этом p
Мы видим, что концентрация гемоглобина повысилась, но практически незаметно, следовательно, статистическая значимость появилась именно за счет объема выборки.
Доверительный интервал может быть высчитан не только для средних значений, но и для пропорций (и отношений рисков). Например, нас интересует доверительный интервал пропорций пациентов, которые достигли ремиссии, принимая разработанное лекарство. Допустим, что 95 % ДИ для пропорций, т. е. для доли таких пациентов, лежит в пределах 0,60–0,80. Таким образом, мы можем сказать, что наше лекарство оказывает терапевтический эффект от 60 до 80 % случаев.
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы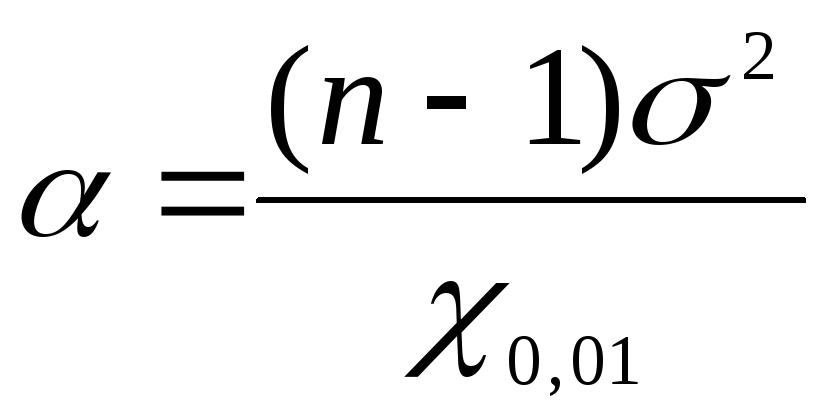 ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
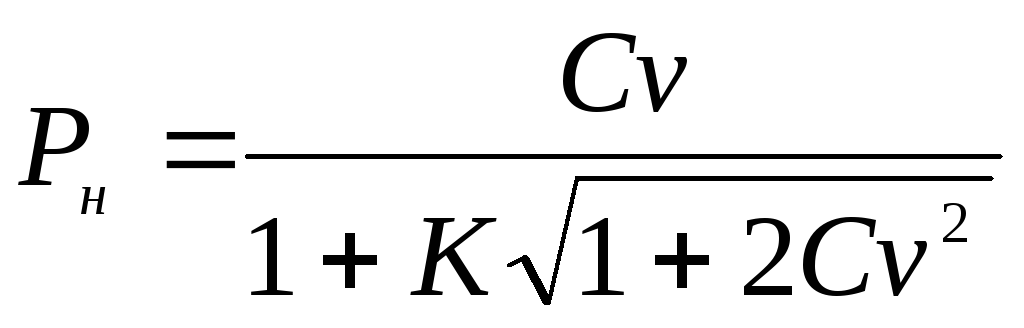 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).











